Written by Mike Mintz et al.
Paper Link: https://aclanthology.org/P09-1113.pdf
Summary
- Motivation
- To use Freebase to give us a training set of relations and entity pairs that participate in those relations
- Contribution
- Avoid overfitting and domain-dependence by using large-scale knowledge base
- Limitation
- Wrongly labeled relations
- False negatives
- Assumption on large data (knowledge base such as Freebase)
Introduction
4가지 RE 방법론
1. Supervised RE
Methods: Corpus의 문장에서 entities가 존재하면 그들 간의 relation을 hand-labeling 한다.
Limitation
- labeling cost
- bias to domain
2. Unsupervised RE
Methods: 많은 양의 text에서 entities 사이의 단어를 추출하고 clustering하여 relation name으로 만든다.
Limitation
- 많은 양의 text와 relation이 필요하다.
- 특정 knowledge base에서 필요로 하는relation name에 맵핑하기 어렵다.
3. Bootstrapping learning
Methods: 적은 수의 패턴을 반복적으로 bootstrapping 한다.
Limitation
- low precision (high false positives)
- semantic drift: a form of language change regarding the evolution of word usage — usually to the point that the modern meaning is radically different from the original usage
4. Distant supervision
Methods
- Large semantic database를 사용해 entity pair에 대한 supervision을 준다.
- Unsupervised 방법론과 달리 classifier의 예측이 database의 정해진 relation name을 사용할 수 있다.
Advantages
Distant supervision은 다음 두 가지 문제를 방지한다.
- over-fitting
- domain-dependence
Methods
Architecture
Distant supervision의 아이디어는 Freebase에서 relation과 entity pair로 구성된 training set을 추출하는 것이다.
Training time
- Named entity tagger를 이용해 Wikipedia 문장에서 모든 entity를 찾아 person, organization, location으로 label을 달아준다.
- 만약 한 문장에서 2개의 entity를 발견하여 이들 간의 관계가 Freebase relations에 포함된다면, feature를 추출한다. 이 추출된 feature vector를 relation의 feature vector에 더해준다.
- 다른 문장에서 발견된 같은 tuple들, 즉 (relation, entity1, entity2) 구성이 같은 tuple들의 features가 더해진다.
- noisy feature를 보완하고 더 다양한 context를 가지는 feature vector를 만들 것이다.
Test time
- 1번 스텝은 동일하다.
- 한 문장에서 발견된 entity pair는 relation을 가진다고 가정한다. 그 entity pair의 feature vector에 문장에서 추출된 features를 더해준다.
- Regression classifier가 entity pair가 발견된 모든 문장에서의 feature에 대해 relation name을 에측한다.
Advantages
- 같은 relation의 여러 번 다르게 언급된(mentions) 정보들을 합칠 수 있다.
- film-director relation에 대한 예제를 살펴보자.
- A: [스티븐 스필버그]의 영화 "[라이언 일병 구하기]"는 실화에 기반했다.
- B: 앨리슨은 아카데미 수상작이자 [스티븐 스필버그]가 연출한 "[라이언 일병 구하기]"를 공동 제작했다.
- B에는 없는 정보인 "라이언 일병 구하기"가 영화라는 정보가 A에서 추출될 수 있다.
- film-director relation에 대한 예제를 살펴보자.
Features
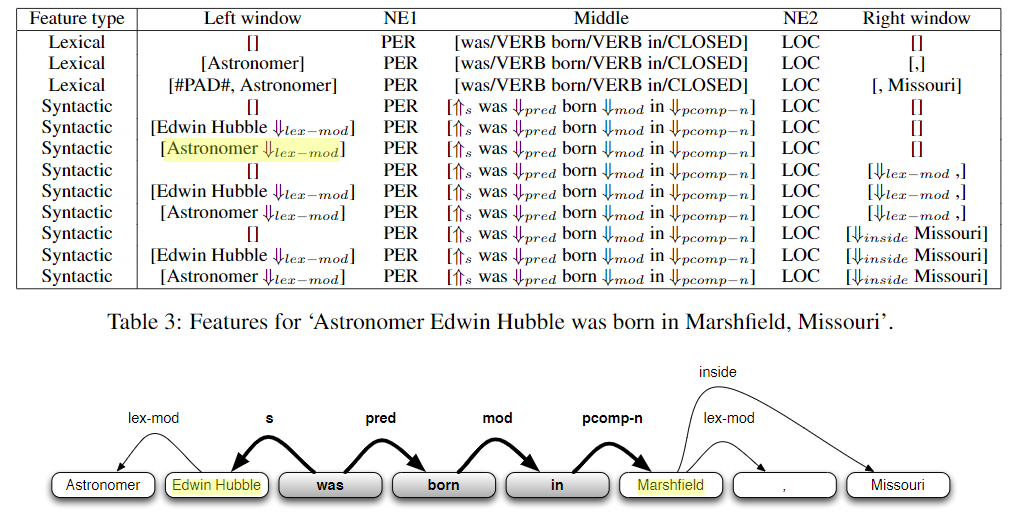
- Lexical features
- The sequence of words between the two entities
- The part-of-speech tags of these words
- A flag indicating which entity came first in the sentence
- A window of k words to the left of Entity 1 and their part-of-speech tags
- A window of k words to the right of Entity 2 and their part-of-speech tags
- Syntactic features
- A dependency path between the two entities
- For each entity, one ‘window’ node that is not part of the dependency path
- Window node
- 두 entity와 연결은 되어 있지만 dependency path의 일부는 아닌 노드이다.
- Named entity tag features
- Tagger를 이용해 각 단어에 label을 붙인다.
- Labels: {person, location, organization, miscellaneous, none}
- Conjunction
- 각각 feature는 앞서 말한 attributes에다가 named entity tags를 더한 conjunction으로 이뤄져 있다.
- Low recall, high precision feature를 만들어준다.
- Positive로 예측 → 실제론 Negative인 경우보다 (False positive)
- Negative로 예측 → 실제론 Positivie인 경우(False negative)가 더 많다.
- Large dataset을 사용하기 때문에 같은 relation의 tuple이 자주 등장한다.
Results
- Held-out evaluation (PR curve)
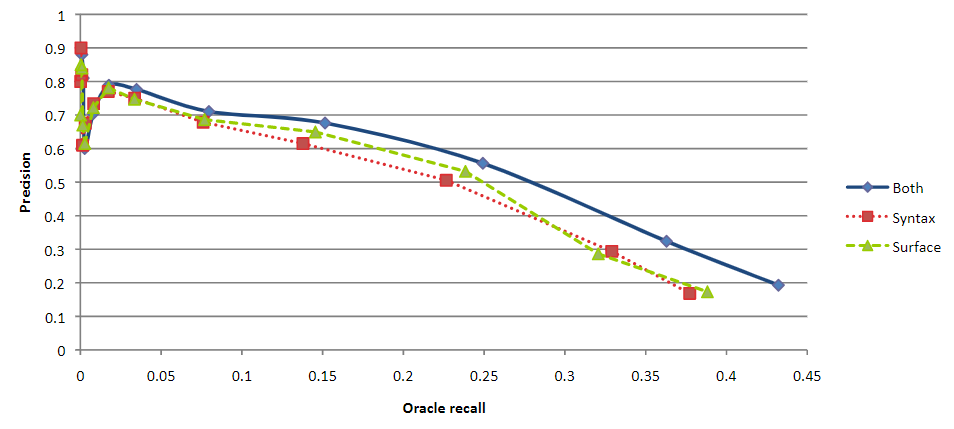
- False positive에 고통받고 있지만, oracle recall이 최대치일 때, Syntax와 Lexical을 둘 다 사용하는 것이 좋은 precision을 보였다.
2. Human evaluation

- Syntactic만 사용하거나 Syntactic + Lexical을 사용하는 경우가 성능이 좋았다.
3. High-weight features for several relations

- Classifier
- Input: an entity pair and a feature vector
- Output: a relation name and a confidence score based on the probability of the entity pair belonging to that relation
- Once all of the entity pairs discovered during testing have been classified
- They can be ranked by confidence score and used to generate a list of the n most likely new relation instances
Discussion & Conclusion
They suggest that syntactic features are indeed useful in distantly supervised information extraction where
- the individual patterns are particularly ambiguous
- they are nearby in the dependency structure but distant in terms of words.
Q&A
- How can we reduce the risk of false negatives and wrong label problems?
- How does distant supervision benefit from syntactic features (rather than lexical features alone)?
- Is knowledge base always needed for distant supervision?
- [5 Features] " Each feature describes how two entities are related in a sentence, using either syntactic or non-syntactic information. -> where is non-syntactic information?
- [figure2] What is oracle recall? - It's hard to understand what the graph shows.
반응형


