Written by Yu Meng et al.
Paper Link: https://arxiv.org/pdf/2010.07245.pdf
Summary
- Motivation: To suggest a weakly-supervised text classification model trained on only unlabeled corpus without external sources.
- Contribution: 1) no need for external sources like Wikipedia. 2) using indicative words for category and predicting the masked ones. 3) comparable text classification performance compared to (semi-) supervised baselines.
- Limitation: Heuristic tuning required for selecting indicative words and constructing category vocabulary.
Introduction
Text classification: a classic task in NLP (e.g. spam detection, sentiment analysis).
Annotation cost: Previous approaches require large-scale labeled documents with a good number of human-labeled documents as training data.
Pre-trained language model is trained on large-scale unlabeled corpus and can capture “high-order, long-range semantic dependency” in sequences.
Weakly-supervised text classification: only label names are provided and the classifier is trained on unlabeled data
- Limitation: Need of external knowledge sources
Methods
- General knowledge for understanding category
- Feature extracted for classification
- Self-training using LM
Contributions of LOTClass
- Suggest weakly-supervised text classification model using PLM without external knowledge sources like Wikipedia.
- Suggest a methods for finding indicative words for categories and masked category prediction.
- Can generalize well using self-training on unlabeled corpus.
Methods
3.1 Category understanding via label name replacement
Human can understand semantics of label names by correlated keywords.
To learn category vocab using PLM,
- BERT produces contextualized embedding vector of label name: h
- MLM (masked language modeling) head produces probability distribution over entire vocab V
$$p(w|h) = Softmax (W_2 \sigma (W_1h+b))$$
To replace original label name, select top-50 predicted similar words.
Form category vocab of each class using top-100 words ranked by how many times they can replace the label name.
e.g. Label name: “sports”
→ Replaced with top-50 words predicted by MLM
- Word distribution can be different from its surrounding context!
- 1: 스포츠 → baseball, 2: 뽐내다 → featured
→ Category vocabulary consist of top-100 frequently replaced words.
3.2 Masked category prediction
How human perform classification? Focus on category-indicative words in a corpus!
💡 First idea: Highlight every occurrence of category vocabulary entry in the corpus!
→ Limitation
- Context is important: Not every occurrence of category words indicates the category.
- Vocabulary can not cover everything: Coverage of category vocab is limited.

💡 Okay, then let’s try Masked Category Prediction
LM produces contextualized word-level category supervision (like pre-trained MLM).
To predict implied category of a word masked.
Notation
- $w$: category-indicative word for class $c_w$
- $S_{ind}$: a set of category-indicative words + category labels
Methods
- Mask $w$ with [MASK] token and train model to predict $w$’s indicating category $c_w$
- CE loss with linear layer
$$L_{MCP}=-\Sigma_{(w,c_w)\in S_{ind}} logp(c_w|h_w)$$
Advantage: infer categories based on the word’s contexts instead of memorizing context-free category keywords.
3.3 Self-training on entire unlabeled corpus
- Many unlabeled documents not seen by the model in MCP, which have no detected category keywords.
- During MCP, the classifier predicts categories with masked words but have not been applied on the [CLS] token.
- [CLS] token offers information about the entire sentence.
💡 Self-training
: Iteratively use the model’s current prediction P (student) to compute a target distribution Q (teacher) which guides refined training.
KL divergence loss
: How similar are two distributions? (Let’s make P close to target distribution Q)
$$L_{ST} = KL (Q||P) = \Sigma \Sigma q_{ij}log {{q_{ij}} \over {p_{ij}}}$$
(i: instance, j: class)
Soft labeling derives target distribution $q_{ij}$ by enhancing high-confidence predictions while suppressing low-confidence ones (큰 확률은 더 크게, 작은 확률은 더 작게):
$$q_{ij} = {{p^2_{ij} / f_j} \over {\Sigma_{j'} (p^2_{ij'} / f_j')}}$$
(f: sum of all p)
Model predictions $p_{ij}$ is produced by applying the classifier trained through MCP to [CLS] token of each doc:
$$p_{ij} = p(c_j|h_{d_i:[CLS]})$$
- The choice of Q: Hard labeling and soft labeling
- We prefer soft labeling.
- Hard labeling is more prone to error propagation.
- Soft labeling computes target distribution for every instance and no confidence thresholds need to be preset.
Experiments
Dataset statistics.

Test acc.
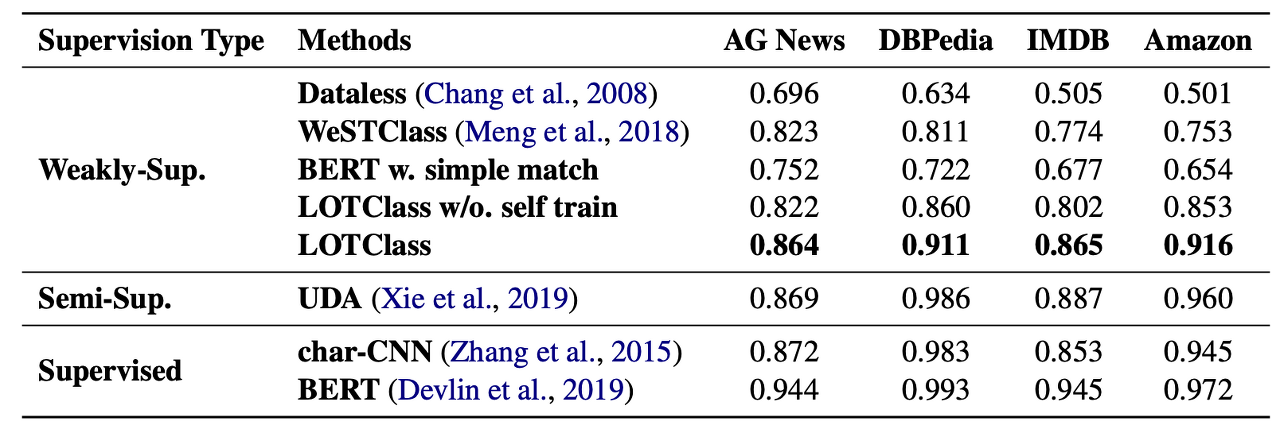
Analysis
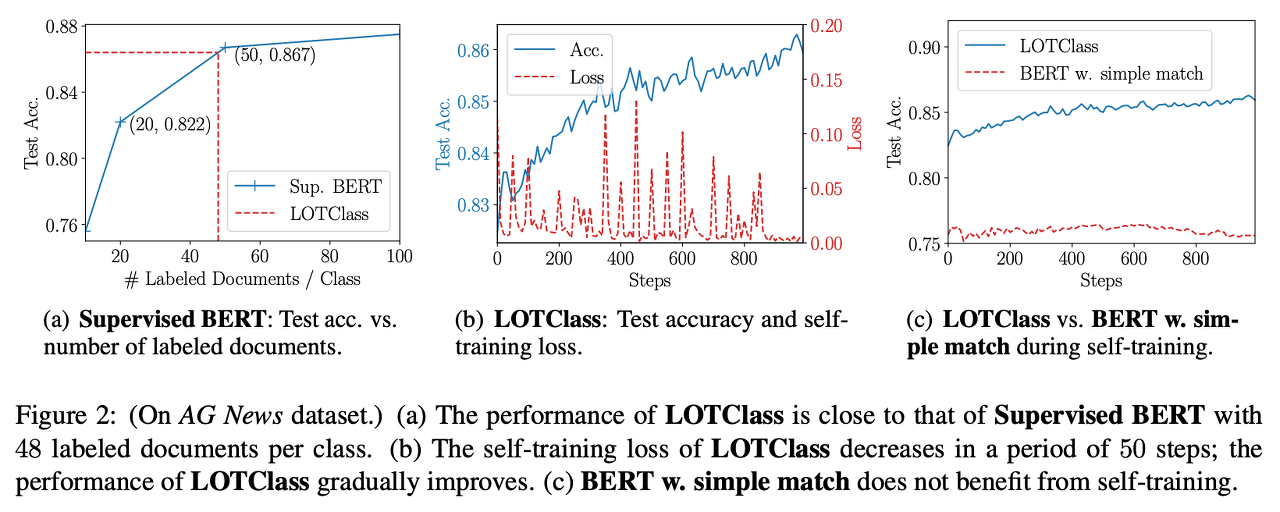
(a) How many labeled docs are label names worth?
→ Performance of LOTClass is close to that of Supervised BERT with 48 labeled doc per class.
- (해석) BERT에 supervision을 주었을 때, unlabeled corpus와 label name만으로 학습한 LOTClass와 성능이 같아지려면, class 당 48개의 labeled documents 주어야 한다?
(b) Test accuracy and self-training loss when training LOTClass.
- Loss decreases within a period of 50 steps (= update interval for target distribution Q)
- Model refining itself on unlabeled data iteratively through ST, performance improves.
(c) LOTClass vs. BERT v. simple match during ST.
- BERT v. simple match does not seem to benefit from ST.
- Why? Documents containing label names may not be actually about the category (like homonym or polysemy? 동음이의어/다의어)
- Noise from simple match can cause the model to high-confidence wrong predictions
- → Prevents model from finding correct classification signals while ST.
Related Works
Semi-supervised text classification
How to leverage unlabeled data?
- Augmentation-based: generate new instances and regularize the model’s prediction to be invariant to small changes in input.
- Graph-based: text networks with words, documents, and labels and propagate labeling information along the graph using GNN.
→ 🤔 I’m not sure whether it’s a good categorization...
Weakly-supervised text classification
categorizes text documents based only on word-level descriptions of each category without the need of labeled documents.
- Distant supervision: Use Wikipedia to interpret label name semantics and derive document concept relevance.
- Learning from general knowledge without any unlabeled domain-specific data → “dataless classification”
- Topic models: word-aware topics by biasing Dirichlet priors and to infer posterior document-topic assignment.
- ☑️ Neural approaches: assign documents pseudo labels to train classifier by 1) generating pseudo doc or using LMs to detect category-indicative words.
Zero-shot text classification
generalizes the classifier trained on a known label set to an unknown one without using any new labeled documents.
- Transferring knowledge from known to unknown label set relies on:
- semantic attributes and descriptions of all classes
- correlation among classes
- joint embeddings of classes and docs
- Zsh learning still requires labeled data for the seen label set and cannot be applied to cases where no labeled docs for any class is available. → 🤔 This study does not require any labeled docs, so it can be used for zsh setting?
Discussion Topics
General
- What parts of the framework can you consider or change if you apply LOTClass to computer vision or medical problems?
Methods
- Possible limitation of Category replacement & Masked category prediction
- How self-training works and helps to improve generalization ability?
- cf. Rethinking Pre-training and Self-training https://arxiv.org/abs/2006.06882
Experiments
- Weakly- vs. semi-supervised learning
- What additional experiments can you design to improve the delivery of the paper's messages?
Q&A
- I don't understand the general procedures in Section 3.3 self-training.
- I've never seen Kullback-Leibler Divergence as loss function before. Is it common in self training?
- In self-training, is Q distribution from softmax of model prediction?
- Self-training is just to apply contextualized embedding learned by label-relevant words to [CLS] tokens?
- I'm a little bit confusing. Can LOTClass outperfom in the few/zero-shot setting?
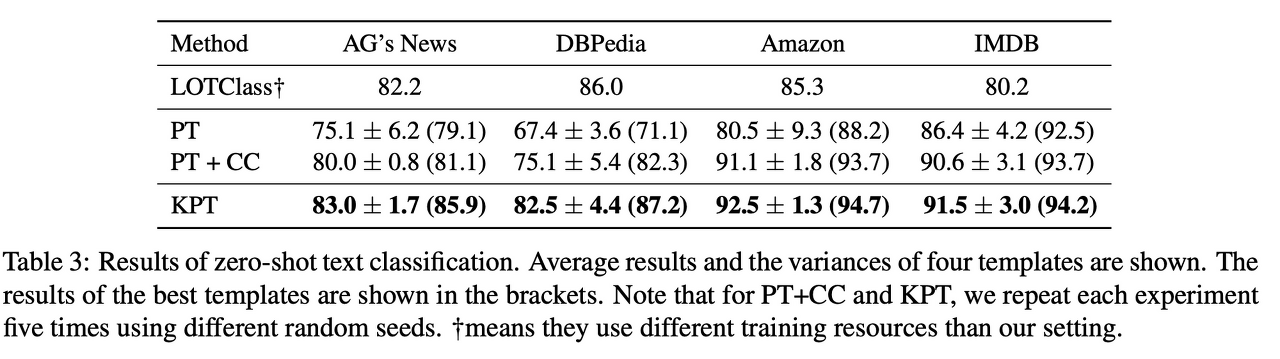
- Can LOTClass this model show good performance with language models for long sequences like Longformer or BigBird?


