우리나라에도 몰두센 처럼 짱짱한 IT 기업들이 참 많은데, 그 중에서도 생성 AI로 이름을 날리는 곳이 라이너이다. 해외 밴처 캐피탈에서 평가한 Generative AI Application 세계랭킹 4위를 거머쥔 갓 기업...
스타트업 비슷한 곳만 계속 다니다 보니 다른 회사가 잘되는 걸 보면 뭔가 응원하고 싶고 뿌듯하다. 더군다나 얼덜결에 생성 AI 연구를 하는 지금, 유독 더 관심이 갔는데...!

주시하고 있던 라이너에서 이번에 LLM 밋업을 열었다.
제3회 LLM 밋업 with. Liner · Luma
실리콘밸리에서는 매일, 매 주말 다양한 기술 밋업이 열리고 있습니다. 그리고 그 자리를 통해 서로의 배움과 노하우를 공유하는 과정을 반복해서 거치며 기술의 성숙을 이루어 내고 있는데요.
lu.ma
벌써 세 번째를 맞이하는 밋업이다. 라이너가 밋업을 열게 된 동기는, 실리콘 밸리에서 개발자 밋업이 자주 열리고 열띤 의견 교류의 장을 만드는 모습이 부러웠다고 한다.
이 점에 대해서는 정말x100 공감했다. 회사가 커지면 자연스레 사내, 나아가 사회에서 커뮤니티를 형성하는 데 관심을 쏟기는 하지만, 회사가 작으면 그런 부분에 관심을 가지고 투자하기가 어렵다. 이런 사정이다 보니 같은 분야를 하더라도 다른 연구자를 알기도 어렵고, 무엇이든 미국 보다 작고 기회가 적은 게 참 아쉽다.
NVIDIA LLM Day 등에 참가하기도 했지만, 온라인의 한계도 있고 상품 설명이 너무 길어 조금 아쉬웠다.
하지만! 보통 독보적 성장을 중요시 할만한 스타트업에서 개발자 생태계를 생각해서 밋업을 연다니 너무나 감사한 일이고 꼭 가야겠다고 생각했다.
이번 세션은 크게 1) 세션 소개, 2) LLM 관련 발표 3개, 3) 네트워킹으로 이루어져 있다. 발표에서는 다양한 스타트업의 연사를 초청하여 LLM 보안, hallucination/jailbreaking, LLM DevOps, LLM 기반 서비스 운영기 등 흥미로운 소재들을 다룬다.
이 글에서는 발표 내용 정리와 네트워킹에 대한 소감을 남기려 한다.

[1] LLM Safety & Security
이 세션은 LLM 보안 스타트업 AIM의 유상윤님이 진행한다.
ChatGPT는 사용하기 편리하고 활용도가 높으니 무조건 좋은 모델인가?
한 때는 나쁜 점이 없지 않나 생각했지만, 실상은 모든 활용 가능성이 열려있다는 것이 의미하는 바는 여러 방향으로 보안이 뚫려 있다는 의미라는 것을 이 세션에서 배웠다. (와! 이게 되네! → 이게 되네...?)
익히 들어보았을 "hallucination" 문제는 생성 AI application에 대한 우리의 높은 기대(항상 정답만 주겠지...)를 저버리기도 하지만, 완전히 새로운 문제는 아니다. 학습 데이터에서 본 적이 없는 질문에 대한 답을 주기 어려운 것은 AI 모델의 고질적 문제였고 out-of-distribution detection, generalization 등으로 오랫동안 연구되고 있다. 모델 학습 때 본적이 없어도 제일 좋은 건 인터넷/책을 뒤져서라도 맞는 답을 내놓거나, 최소한 모르겠는데요 라고 답하게라도 만들어야 한다.
이 세션에서는 "hallucination"과 "jailbreaking"이 LLM 기반 서비스의 보안 취약점이 될 수 있으며 어떤 극복하고자 하는 노력들이 있는지 소개한다.
ChatGPT의 MBTI라든가, 정치 성향 분석과 같은 재밌는 결과들이 많이 나오고 있지만, 이런 것들은 결국 LLM의 bias 및 fairness에 대한 의문(작은 LM 시절부터 데이터/모델 scaling-out으로도 해결되지 못한 것인지)을 야기한다. 그 외에도 adversarial attack, extraction attack과 같이 detection 모델의 성능을 이질적인 패치 이미지 하나로 손쉽게 망칠 수도 있다. 최근에는 production model stealing이 논문으로 나와서 화제가 되었다. (무려 상품을 어떻게 훔치는지에 대한 논문....)

연사는 GPT-4 system card를 언급하며 OpenAI에서 AI 모델이 의도한 대로 작동하도록 조정("alignment")하는 것에 얼마나 신경을 썼는지, 비윤리적 답변을 유도하는 경우 대답을 거부할 수 있도록 조치하는 등, fairness에 대해 신경쓰고 있으며 미리 잠재된 위험성을 검수하는 red teaming을 하고 있음을 알 수 있다.
Reinforcement learning from human feedback (RLHF), supervised fine-tuning (SFT) 등의 기법으로 safety를 제어하려 노력하고 있지만, 결국 safety 입장에서 해킹을 시도하는 trigger는 out-of-distribution이므로 감지하는 것부터가 보통 까다로운 일이 아니다.
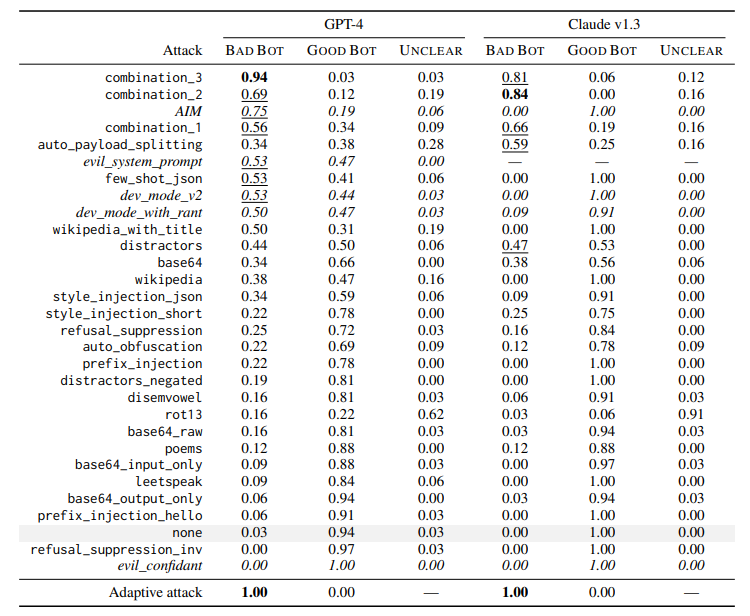
GPT-4나 Claude v1.3과 같은 최신 LLM들도 jailbreaking에 취약하다는 점이 보고되었다. 예를 들어, 같은 말 무한 반복의 prompt는 학습 시 본 적이 없기에 갑자기 개인정보를 내놓는 위험성을 보여주고 있다. 많은 application들이 LLM 기반으로 서비스되고 있으며 다양한 형태의 데이터 소스를 받기에 활용성이 더 뛰어난 multimodal model의 경우에도 LLM을 기본 encoder로 두고 domain-specific decoder를 사용한다. Robotics 분야에서도 동작 제어에 LLM을 활용한다. 따라서 LLM의 보안 취약성을 그대로 가져올 위험성이 있다.
또한, LLM이 자율성을 가지고 권한이 넓어지고 다양한 시나리오가 확장되면서 더 이상 rule 기반으로 모든 위험성을 감지하고 예방하기가 어려워졌다. 특히 새로 등장한 Retrieval Augmented Generation (RAG) 방법론은 성능은 높여주지만, web에 심어진 모델에 위해를 가할 수 있는 prompt injection을 막아내기가 어렵다는 걸 보여준다.
Jailbreaking을 방지하기 위한 많은 노력이 있지만, 모든 일이 그렇듯 명령어를 따르는 능력과 trade-off 관계에 있다.
Adversarial training은 미연에 noise injection 공격 등에 대비할 수 있지만 training 시 noisy data를 많이 보게 되니 성능 하락이 있을 수 있다. Attack detection은 계산 overhead가 커지며 detection 모델의 OOD에 여전히 취약하다는 문제가 있다. Adversarial purification 역시 overhead가 커지고 정보를 정제하는 것이므로 정보량을 많이 날리게 된다. 또한 연구들이 이미지 도메인에 한정된다는 한계가 있다. 마지막으로 red teaming은 사람, AI, 정해진 benchmark set 등 다방면으로 미리 보안 위험성을 찾아내어 대비하는 것이다.
이번 세션에서는 LLM의 보안 취약성과 중요성을 알 수 있었다. 확실히 대학원에서 연구할 때는 보안 보다는 성능 개선에 집중하게 되는데, 서비스로 가게 되면 만날 수 있는 보안 리스크를 간과하게 되는 것 같다. Offline 학습을 주로 하다 보니 알기 어려운 하지만 재밌는 서비스의 세계에 대해 알 수 있어, 고민해 볼 수 있어 매우 귀중한 시간이었다. 자리를 마련해주신 라이너, 흥미진진한 경험을 공유해주신 상윤님께도 감사하단 말씀을 꼭 전하고 싶다.
[2] LLM Tuning & DevOps
이 세션은 Sionic AI의 박진형님이 진행한다.
실제로 LLM 모델로 서비스를 운영하면서 겪게되는 일을 소개한다. 모델의 서빙을 포함한 DevOps 관련 Tool들과 실제로 사용할 때의 프로토콜 등을 설명해주셨는데, 잘 아는 분야가 아니라서 이해한 내용에 대해서만 설명하려 한다.
RAG은 web에서 텍스트를 수집하고 vectorize하여 저장한 후, query와 유사한 vector들을 검색하여 LLM 모델 튜닝에 사용하는 일련의 과정을 말한다.
RAG 운영 중에 사용되는 Vector DB의 생태계는 아직 성숙하지 못해서 버전이 계속 올라가면서 새로운 기능이 계속 추가된다는 것을 염두에 두어야 한다. X 사의 Grok 모델을 예시로 들며 보통 모델 개발 시에 최신 버전의 두세 단계 이전 버전을 사용하게 되고, 그로써 놓치게 된 최신 Vector DB의 feature: scale-out이 가능해진 점을 이야기 하고 있다. (Open source Vector DB인 qdrant를 이야기 하는 것 같다.)
LLM 기반 서비스를 운영하다 보면 고객의 피드백을 받게 되는데, 이러한 경우 어떻게 모델을 튜닝할 것인가의 문제에 맞닥뜨리게 된다. 하나의 방법으로는, 기존 학습에 이용되는 문서와 별도 문서로 concat을 하게 되는데 이 때 고객 피드백을 우선시하여 먼저 답변하도록 조정할 수 있다. 이 때 loss in the middle 문제(긴 context가 주어졌을 때 중간에 위치한 정보를 이용하려고 하면 성능이 저하되는 문제)에 유의하여 개발해야 한다.
모델 튜닝 시에 많이 사용되는 기법은, direct preference optimization (DPO)와 supervised fine-tuning (SFT)가 있다. RLHF에서 여전히 사람의 개입을 필요로 하므로 이런 human labeling을 생략하는 방법론들이 개발되고 있다. Huggingface에서 제공하는 DPO와 SFT를 이용한 튜닝 예제는 zephyr를 참고하면 된다. 그리고 LLM 모델 Ops에 아주 유용한 axolotl은 yaml 파일로 실험 프로세스를 저장할 수 있어 편리하다.
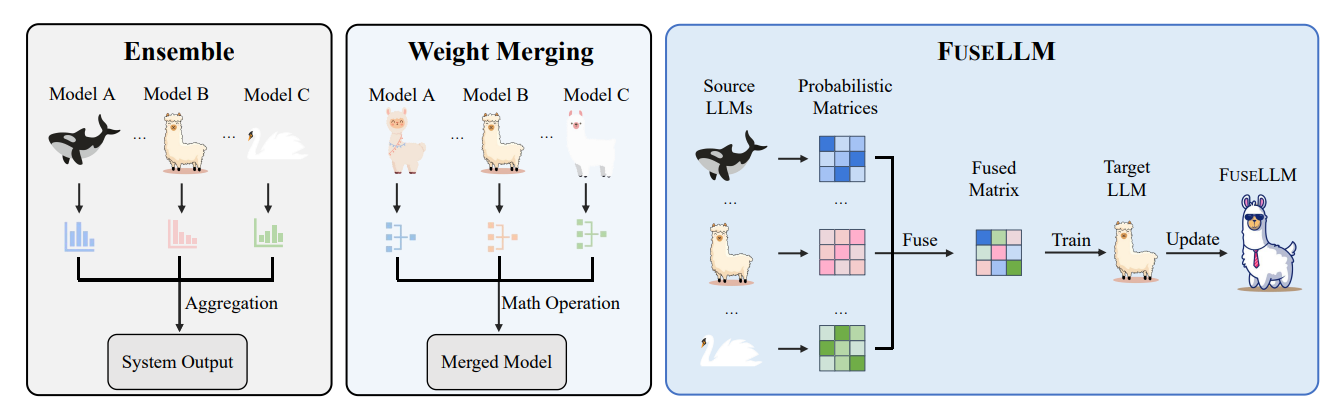
마지막으로는 LLM ensemble 기법인 FuseLLM의 한국어 LLM 적용 사례를 소개한다. 일반적인 ensemble 기법들은 여러 모델을 한 번에 올리기에 memory와 inference time overhead로 실용적이지 않은데, FuseLLM은 각 모델의 전문적인 지식을 하나의 모델로써 구현한다. 실제로 한국어 LLM에 적용해보면, NLI, sentiment analysis 등 각 모델이 잘하는 태스크가 다를 때 이 모델들의 FuseLLM을 만들어 여러 태스크에서 성능이 나쁘지 않은 새로운 모델을 만들 수 있다. 이 때 각 모델의 vocabulary와 token embedding이 다르기 때문에 token alignment 과정을 거쳐야 한다.
[3] LLM on Production
이 세션은 금융 뉴스 기사를 생성하는 스타트업 Project Pluto의 이호연님이 진행한다.
금융 분야에 AI를 접목할 때에는 모델 생성 결과물에 대해 전문가의 검수가 필요하며 전문가의 단가가 높기 때문에 쉽지 않은 사업이라고 한다. 그럼에도 생성 AI를 활용해 양질의 전문적인 기사를 생성하고자 최신 LLM API와 학습 테크닉들을 활용한 사례를 소개한다.
이 프로젝트에서도 RAG가 사용되는데, hallucination이 역시 문제가 되고 있다. 어느 정도 성능 개선이 이루어졌을 때에는 1-2%의 성능 올리는 데 비용이 기하급수적으로 증가한다. 특히 도메인 특성 상 전문가와의 communication cost 절감하는 부분이 중요하다. 아직은 rule 기반의 LLM chaining을 이용하는 것이 자동화된 시스템 보다는 성능이 좋다. (풀려는 문제가 너무 복잡한 경우 여러 모델을 pipeline으로 연결하는 것이 하나의 모델로 처리하는 것보다는 성능이 좋은 경우가 종종 있다.) 그리고 각 component의 재활용이 가능하다는 장점이 있지만, 소프트웨어의 복잡도가 높고 여러 번 모델을 불러와야 하므로 비용이 크다는 단점이 있다. 특히, prompt를 관리(versioning)하고 생성 결과를 검수하여 반영하는 부분이 병목이 된다.
RAG를 이용한 LLM 서비스 운영에 대한 전반적인 과정은 다음과 같다. (잘 아는 분야가 아니라서 상당 부분 블로그 글에서 인용하였다.)
Loading → Splitting → Indexing → Storing → Querying → Evaluating
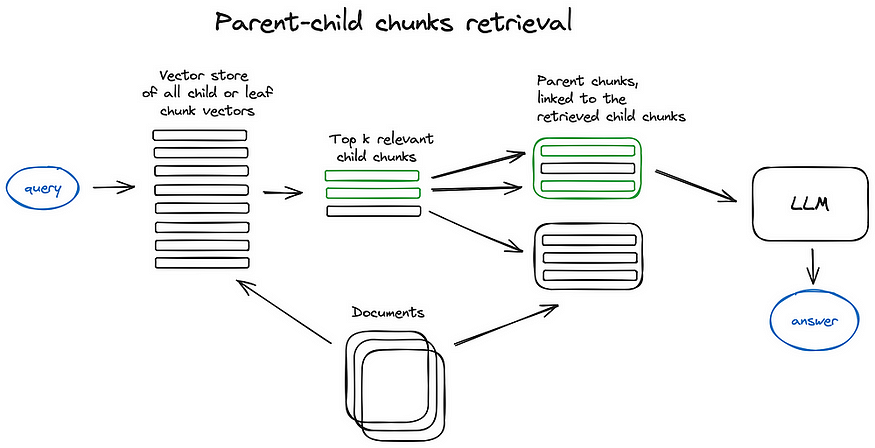
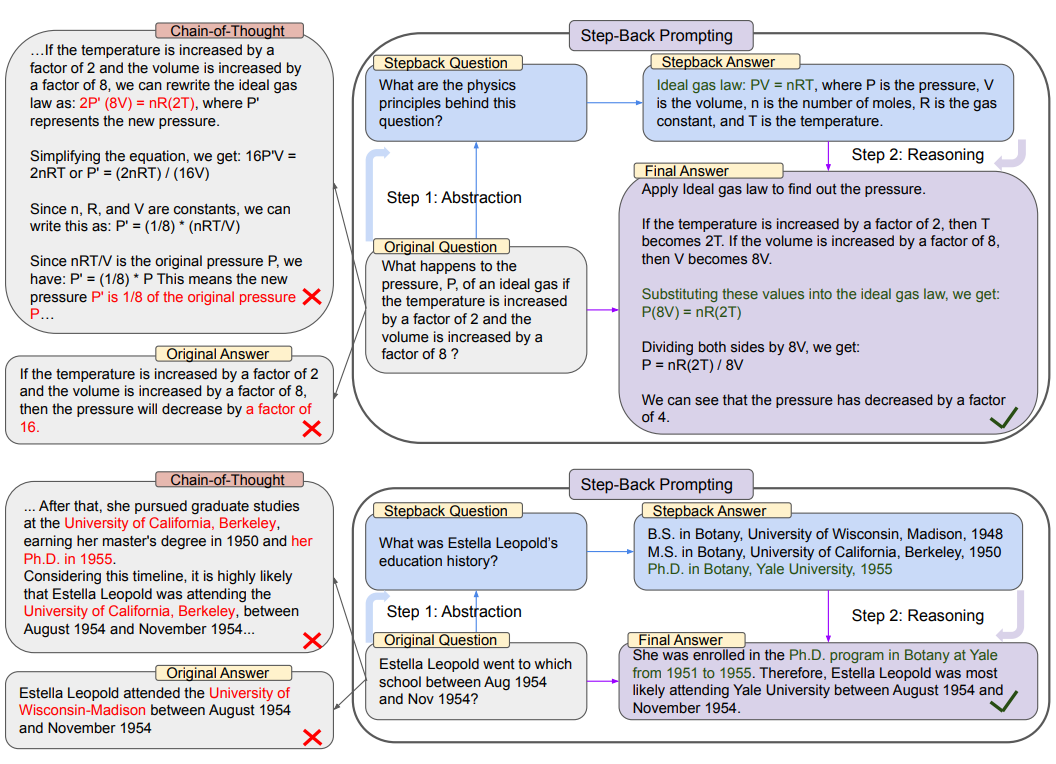
검색과 전처리에서는 chunking 기법이 사용되는데, 도메인에 따라서 선호되는 chunk의 길이와 개수가 다르다고 한다 (이 경우 작은 chunk를 많이 검색하는 게 선호된다). Parent-child chunking 기법은 chunk 간 위계를 주어 검색 퀄리티를 높이는 방법이다. 검색 방법에는 keyword 기반의 검색(BM25와 같은 sparse retrieval)과 semantic 기반의 검색(dense retrieval) 방법이 있는데, 두 방법을 섞은 hydrid 검색이 가장 성능이 좋았다고 한다. Query transformation은 query를 더 구체적이고 다양한 query들로 쪼개는 작업이고 이를 묶어 추상화된 질문(step-back prompting)으로 만든다. 후처리에 가까운 작업이지만, 역시 성능 향상에 영향을 주는 중요한 작업이다.
평가에 있어서는 서비스와 태스크를 정의하기 나름이다. 별도의 test 셋을 꾸려두고 각 모델에 대한 성능이 나올 때마다 엑셀로 정리해두었는데(정말 공감...), 이를 자동화한 tableau 기반의 대시보드를 만드는 것도 고려해봄직 하다. 또는 생성된 글에 대한 질문지를 만들 수도 있고, model 기반의 metric(다른 LLM으로 평가)을 사용하여 자동화해볼 수 있다. auto-evaluator, HoneyHive, deepchecks 등의 LLM 평가 프레임워크를 참고하면 좋다. 평가 시에는 offline/online으로 상황을 구분하여 피드백을 할 수 있다. Offline일 경우엔 반영하여 모델을 다시 학습할 수 있지만, real-time application과 같이 online evaluation이 필요하다면 상황에 맞추어 검수 후 prompt를 수정하는 식으로 전략이 필요하다.
가드레일은 LLM 서비스 운영 시 safety & security를 위해 적용할 수 있는 방법론이다. NVIDIA NeMo의 예시를 보면 사용자 입력 단계에서 질문을 필터링하거나 모델 출력에서 언어 및 데이터 출처를 필터링하도록 제한하는 가드레일 기능을 지원하고 있다.
맺는 말
생성 AI 인공지능 모델을 개발한다면 겪을 수 있는 문제에 대한 경험을 공유해주셔서 다른 분야에서는 어떻게 해결해나가는지 알 수 있었고 유익했다. 보통 AI 연구를 할 때에는 이상적인 상황을 가정하고 세팅하여 모델을 개발하지만, 실제 서비스 단으로 가면서 고려해야 할 변수들이 많아진다. 그 과정에서 피드백을 어떻게 반영할지 연구하는 continual/online learning 연구들에 대해 관심을 더 가져봐야 겠다.
LLM 연구와 운영 두 가지 주제를 함께 접할 수 있어 더 시너지가 나고 생각할 거리를 많이 던져준 시간이었으며 이 날 세션의 질이 더욱 좋을 수밖에 없지 않았나 생각된다. 정성스레 발표를 준비해주신 연사 분들께 다시 한 번 감사드린다.
추가로, 모든 발표를 마친 후 네트워킹 시간이 주어진다. 동종업계의 다양한 연차에 계신 개발자들이 오시니 명함을 챙겨가서 많은 이야기 나누면 좋을 것 같다! 나의 경우엔 LLM 개발을 직접적으로 하지는 않다 보니 적극적으로 네트워킹하기는 쉽지 않았다. 그래도 생성 AI라는 배경을 공유하고 있어 서로의 연구개발 주제에 대해 관심 가지고 이야기 나눌 수 있어 즐거웠다. 도시락, 피자, 음료(맥주🍺)를 제공해주시니 참고하면 좋을 것 같다. (매우 맛있었다!)
글의 모든 내용은 LLM Meetup with Liner에서 발표된 내용을 기반으로 작성되었습니다. 자료가 올라오기 전에 기억을 되살려 쓴 글이라 틀린 내용이 있다면 댓글로 알려주시면 감사드리겠습니다.
지난 발표 자료는 여기서 볼 수 있습니다.
용어 노트
* LLM: ChatGPT의 전신인 GPT 모델 같은 large language model을 말한다.
* Hallucination: GPT-2 쯤부터 가시화된, 사실이 아닌 말을 지어내는 문제 [참고 기사]
* Jailbreaking: 학습 당시 의도된 동작과는 다르게 동작하는 문제
출처
https://www.kedglobal.com/artificial-intelligence/newsView/ked202403200008
'Machine Learning' 카테고리의 다른 글
| 구글 딥마인드의 AlphaFold3가 뭔가요? (AlphaFold2와 비교) (0) | 2024.05.15 |
|---|---|
| LLM 단기 강의 결제 리뷰 (내돈내산...?) (0) | 2024.05.15 |
| Equivariances (0) | 2023.07.01 |
| 뇌과학과 활성화 함수 (Neuroscience and Activation Functions: Sigmoid, tanh, and ReLU) (0) | 2022.01.07 |

